ucore-lab5
本文最后更新于:2023年6月22日 上午
练习解答
实验目的
- 了解第一个用户进程创建过程
- 了解系统调用框架的实现机制
- 了解ucore如何实现系统调用sys_fork/sys_exec/sys_exit/sys_wait来进行进程管理
实验内容
实验4完成了内核线程,但到目前为止,所有的运行都在内核态执行。实验5将创建用户进程,让用户进程在用户态执行,且在需要ucore支持时,可通过系统调用来让ucore提供服务。为此需要构造出第一个用户进程,并通过系统调用sys_fork/sys_exec/sys_exit/sys_wait来支持运行不同的应用程序,完成对用户进程的执行过程的基本管理。
练习0:填写已有实验
我的建议是照着result来完善代码。
这东西不能直接拿lab4做过的用,实在是败笔。
不嫌麻烦的可以参考kiprey
练习1:加载应用程序并执行(需要编码)
do_execv函数调用load_icode(位于kern/process/proc.c中)来加载并解析一个处于内存中的ELF执行文件格式的应用程序,建立相应的用户内存空间来放置应用程序的代码段、数据段等,且要设置好proc_struct结构中的成员变量trapframe中的内容,确保在执行此进程后,能够从应用程序设定的起始执行地址开始执行。需设置正确的trapframe内容。
请在实验报告中简要说明你的设计实现过程。
请在实验报告中描述当创建一个用户态进程并加载了应用程序后,CPU是如何让这个应用程序最终在用户态执行起来的。即这个用户态进程被ucore选择占用CPU执行(RUNNING态)到具体执行应用程序第一条指令的整个经过。
代码:
1 | |
读取文件需要陷入内核态,在load_icode中我们需要完成tf_cs,tf_ds,tf_es,tf_ss,tf_esp,tf_eip,tf_eflags这几个变量的初始化。这注释都已经把答案写出来了。 😆
实验让我们描述用户态进程从被选择执行到具体执行的经过。
建议参考博客园,这里只给出部分关系图以及代码。
proc.c的cluster call internal:
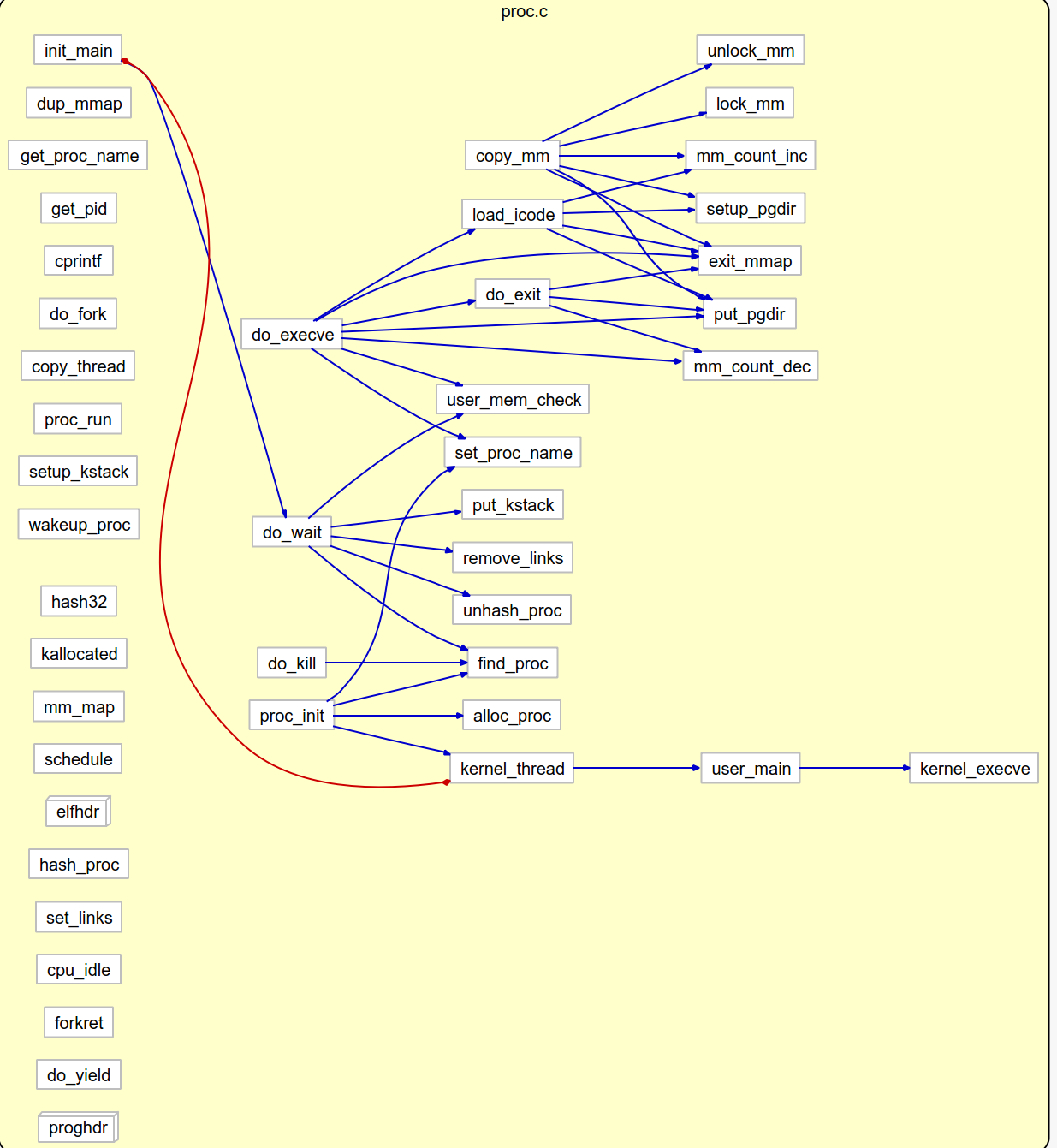
proc.c内部的流程大致如上,不难找到:
1 | |
练习2: 父进程复制自己的内存空间给子进程(需要编码)
创建子进程的函数do_fork在执行中将拷贝当前进程(即父进程)的用户内存地址空间中的合法内容到新进程中(子进程),完成内存资源的复制。具体是通过copy_range函数(位于kern/mm/pmm.c中)实现的,请补充copy_range的实现,确保能够正确执行。
请在实验报告中简要说明如何设计实现”Copy on Write 机制“,给出概要设计,鼓励给出详细设计。
Copy-on-write(简称COW)的基本概念是指如果有多个使用者对一个资源A(比如内存块)进行读操作,则每个使用者只需获得一个指向同一个资源A的指针,就可以该资源了。若某使用者需要对这个资源A进行写操作,系统会对该资源进行拷贝操作,从而使得该“写操作”使用者获得一个该资源A的“私有”拷贝—资源B,可对资源B进行写操作。该“写操作”使用者对资源B的改变对于其他的使用者而言是不可见的,因为其他使用者看到的还是资源A。
代码:
1 | |
练习3: 阅读分析源代码,理解进程执行 fork/exec/wait/exit 的实现,以及系统调用的实现(不需要编码)
请在实验报告中简要说明你对 fork/exec/wait/exit函数的分析。并回答如下问题:
- 请分析fork/exec/wait/exit在实现中是如何影响进程的执行状态的?
- 请给出ucore中一个用户态进程的执行状态生命周期图(包执行状态,执行状态之间的变换关系,以及产生变换的事件或函数调用)。(字符方式画即可)
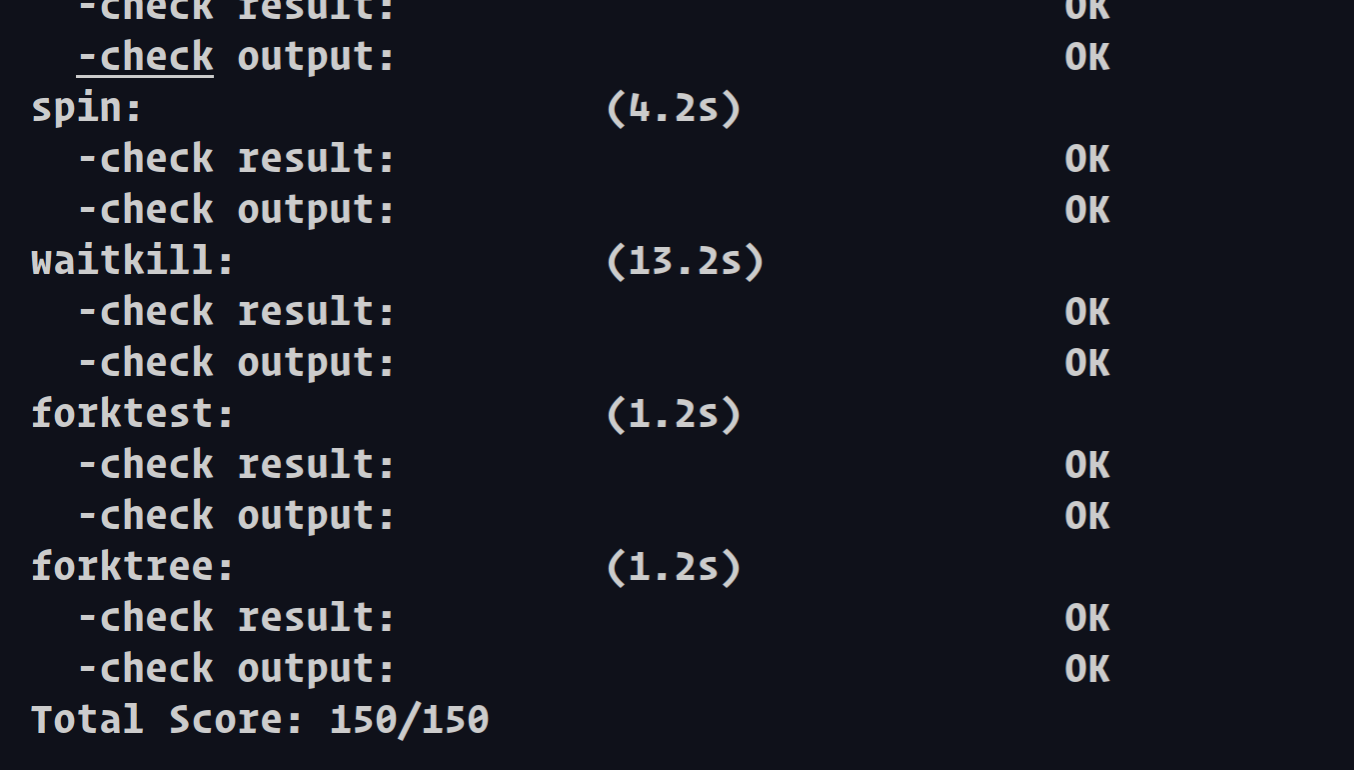
执行:make grade。如果所显示的应用程序检测都输出ok,则基本正确。(使用的是qemu-1.0.1)
注意,前面如果完全正确,参考我上周写的lab4练习二最后一部分更改一下语句就可以拿到136分。
之后参考博客园且自己看提示信息,可以看出这东西确实有bug
我试了试,发现是init_main函数里面,
1 | |
查看kern/mm/pmm.c中的nr_free_pages的函数调用图:
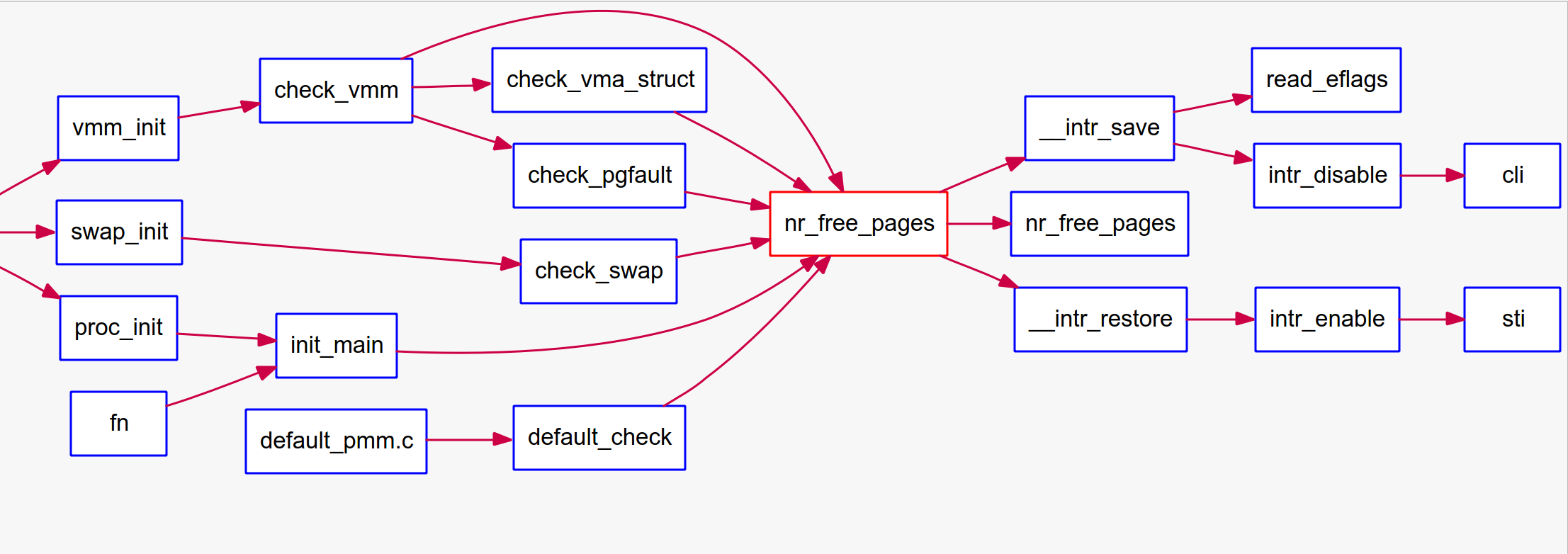
1 | |
在init_main注释这一句即可:
1 | |
- 请分析fork/exec/wait/exit在实现中是如何影响进程的执行状态的?
fork这些调用的都是sys内相应的函数,sys_fork这些又调用的syscall,syscall又调用的诸如do_fork一类。
do_fork之类函数过长,建议自己看
do_fork在练习四写过,这里粘贴一下:
在这个过程中,需要给新内核线程分配资源,并且复制原进程的状态。你需要完成在kern/process/proc.c中的do_fork函数中的处理过程。它的大致执行步骤包括:
- 调用alloc_proc,首先获得一块用户信息块。
- 为进程分配一个内核栈。
- 复制原进程的内存管理信息到新进程(但内核线程不必做此事)
- 复制原进程上下文到新进程
- 将新进程添加到进程列表
- 唤醒新进程
- 返回新进程号
do_exit以及do_wait直接引用博客园
wait的实现
wait的功能是等待子进程结束,从而释放子进程占用的资源。在ucore中wait对应的函数是do_wait。
- 遍历进程链表proc_list,根据输入参数寻找指定pid或任意pid的子进程,如果没找到,直接返回错误信息。
- 如果找到子进程,而且其状态为ZOMBIE,则释放子进程占用的资源,然后返回。
- 如果找到子进程,但状态不为ZOMBIE,则将当前进程的state设置为SLEEPING、wait_state设置为WT_CHILD,然后调用schedule函数,从而进入等待状态。等再次被唤醒后,重复寻找状态为ZOMBIE的子进程。
exit的实现
exit的功能是释放进程占用的资源并结束运行进程。在ucore中exit对应的函数是do_exit。
- 释放页表项记录的物理内存,以及mm结构、vma结构、页目录表占用的内存。
- 将自己的state设置为ZOMBIE,然后唤醒父进程,并调用schedule函数,等待父进程回收剩下的资源,最终彻底结束子进程。
- 请给出ucore中一个用户态进程的执行状态生命周期图(包括执行状态,执行状态之间的变换关系,以及产生变换的事件或函数调用)。
那就直接mermaid了,丑就丑吧 🤐
flowchart TB
ap([alloc_proc])
pi([proc_init])
ap-->pi
r((ready_to_run))
pi-->r
wu([wakeup_proc])
wu-->r
d([调度器])
r-->d
rr((running))
d-->rr
dw([do_wait])
rr-->dw
s((sleep))
dw-->s
de([do_exit])
zz((ZOMBIE))
rr-->de
de-->zz
z((回收销毁))
de-->z
d-->r
rr-->d
s-->wu
扩展练习 Challenge :实现 Copy on Write (COW)机制
给出实现源码,测试用例和设计报告(包括在cow情况下的各种状态转换(类似有限状态自动机)的说明)。
这个扩展练习涉及到本实验和上一个实验“虚拟内存管理”。在ucore操作系统中,当一个用户父进程创建自己的子进程时,父进程会把其申请的用户空间设置为只读,子进程可共享父进程占用的用户内存空间中的页面(这就是一个共享的资源)。当其中任何一个进程修改此用户内存空间中的某页面时,ucore会通过page fault异常获知该操作,并完成拷贝内存页面,使得两个进程都有各自的内存页面。这样一个进程所做的修改不会被另外一个进程可见了。请在ucore中实现这样的COW机制。
由于COW实现比较复杂,容易引入bug,请参考 https://dirtycow.ninja/ 看看能否在ucore的COW实现中模拟这个错误和解决方案。需要有解释。
这是一个big challenge.
不难理解是要干什么。
参考github
我们要修改pmm.c中的copy_range以及处理页错误的page_fault函数:
1 | |
1 | |
结果:
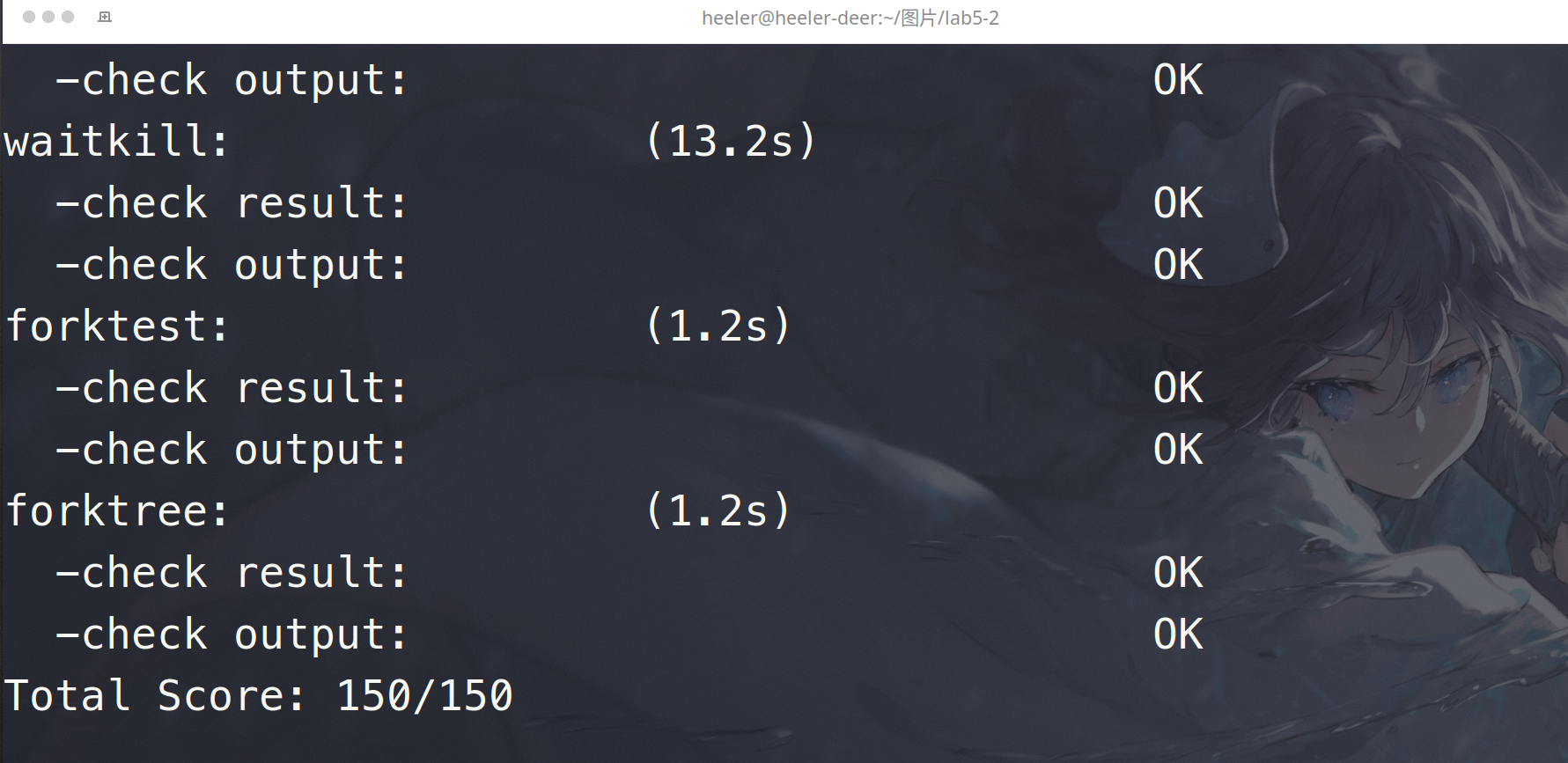
由于一些原因,我并没有按照佬的md做出来Handled one COW fault: reused,所以就鸽了。。
本文作者: Heeler-Deer
本文链接: https://heeler-deer.top/posts/44218/
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!