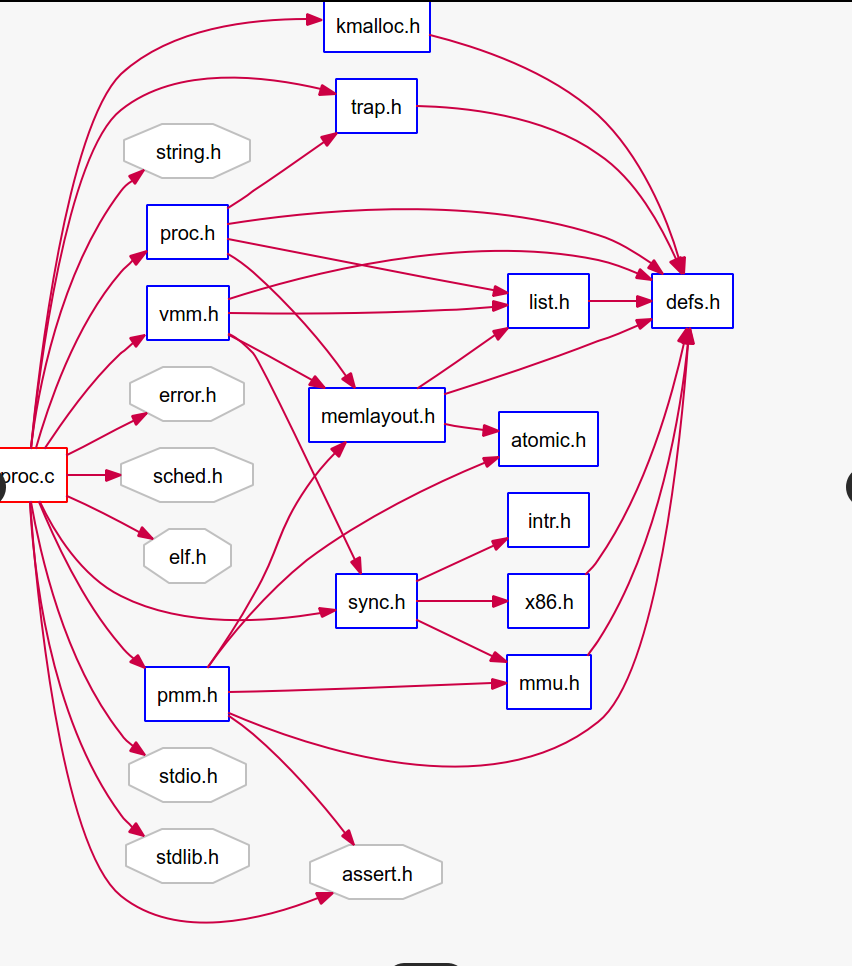
static struct proc_struct * alloc_proc(void){ structproc_struct *proc = kmalloc(sizeof(struct proc_struct)); if (proc != NULL) { //LAB4:EXERCISE1 YOUR CODE /* * below fields in proc_struct need to be initialized * enum proc_state state; // Process state * int pid; // Process ID * int runs; // the running times of Proces * uintptr_t kstack; // Process kernel stack * volatile bool need_resched; // bool value: need to be rescheduled to release CPU? * struct proc_struct *parent; // the parent process * struct mm_struct *mm; // Process's memory management field * struct context context; // Switch here to run process * struct trapframe *tf; // Trap frame for current interrupt * uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT) * uint32_t flags; // Process flag * char name[PROC_NAME_LEN + 1]; // Process name */ proc->state = PROC_UNINIT; proc->pid = -1; proc->runs = 0; proc->kstack = 0; proc->need_resched = 0; proc->parent = NULL; proc->mm = NULL; memset(&(proc->context), 0, sizeof(struct context)); proc->tf = NULL; proc->cr3 = boot_cr3; proc->flags = 0; memset(proc->name, 0, PROC_NAME_LEN); } return proc; }
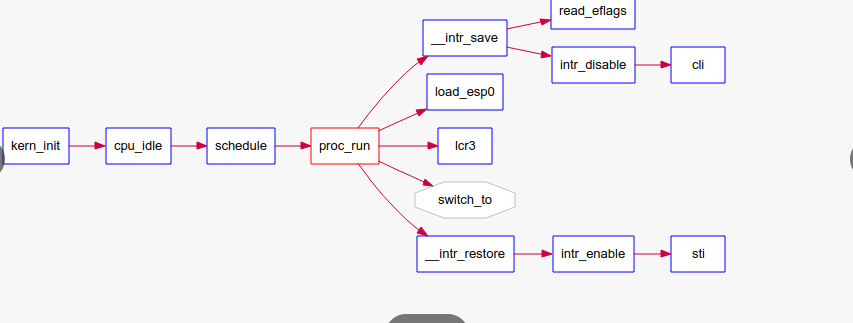
/* * * load_esp0 - change the ESP0 in default task state segment, * so that we can use different kernel stack when we trap frame * user to kernel. * */ //加载内核栈基地址 void load_esp0(uintptr_t esp0){ ts.ts_esp0 = esp0; }
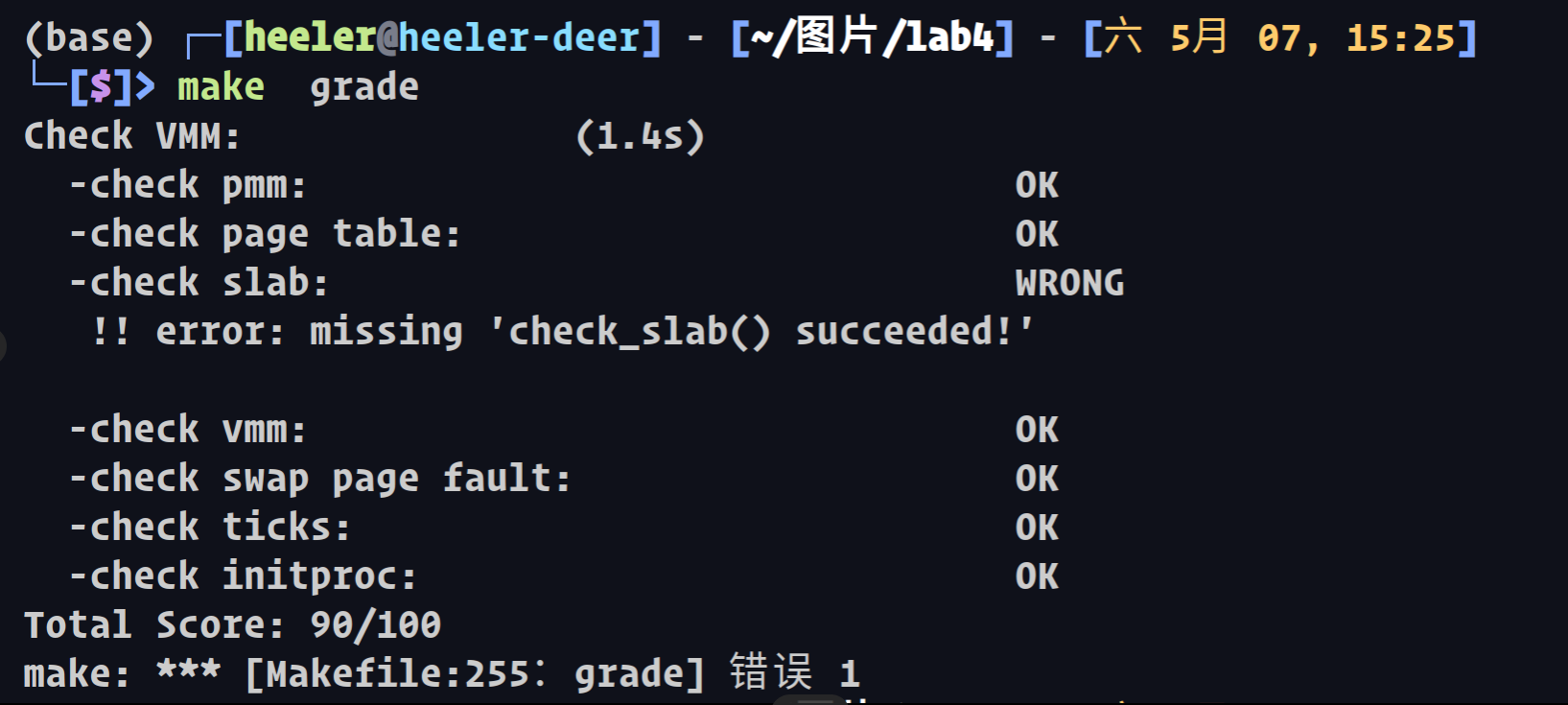
staticvoid *best_fit_alloc(size_t size, gfp_t gfp, int align) { assert( (size + SLOB_UNIT) < PAGE_SIZE ); // This best fit allocator does not consider situations where align != 0 //确认align==0 assert(align == 0); //slob大小 int units = SLOB_UNITS(size);
slob_t *prev = slobfree, *cur = slobfree->next; int find_available = 0; int best_frag_units = 100000; slob_t *best_slob = NULL; slob_t *best_slob_prev = NULL; //循环找到符合条件的单元 for (; ; prev = cur, cur = cur->next) { if (cur->units >= units) { // Find available one. if (cur->units == units) { // If found a perfect one... prev->next = cur->next; slobfree = prev; spin_unlock_irqrestore(&slob_lock, flags); // That's it! return cur; } else { // This is not a prefect one. //如果不能完美的放进去,就更改你的best大小 if (cur->units - units < best_frag_units) { // This seems to be better than previous one. best_frag_units = cur->units - units; best_slob = cur; best_slob_prev = prev; find_available = 1; } }
}
// Get to the end of iteration. //符合条件就分配 if (cur == slobfree) { if (find_available) { // use the found best fit. best_slob_prev->next = best_slob + units; best_slob_prev->next->units = best_frag_units; best_slob_prev->next->next = best_slob->next; best_slob->units = units; slobfree = best_slob_prev; spin_unlock_irqrestore(&slob_lock, flags); // That's it! return best_slob; } // Initially, there's no available arena. So get some. spin_unlock_irqrestore(&slob_lock, flags); if (size == PAGE_SIZE) return0;
cur = (slob_t *)__slob_get_free_page(gfp); if (!cur) return0;
slob_free(cur, PAGE_SIZE); spin_lock_irqsave(&slob_lock, flags); cur = slobfree; } } }