本文最后更新于:2023年6月22日 上午
练习解答
练习0
填写实验
kern/process/proc.c
kern/mm/pmm.c
有需要更改的文件,建议看Kiprey
练习1
练习1: 使用 Round Robin 调度算法(不需要编码)
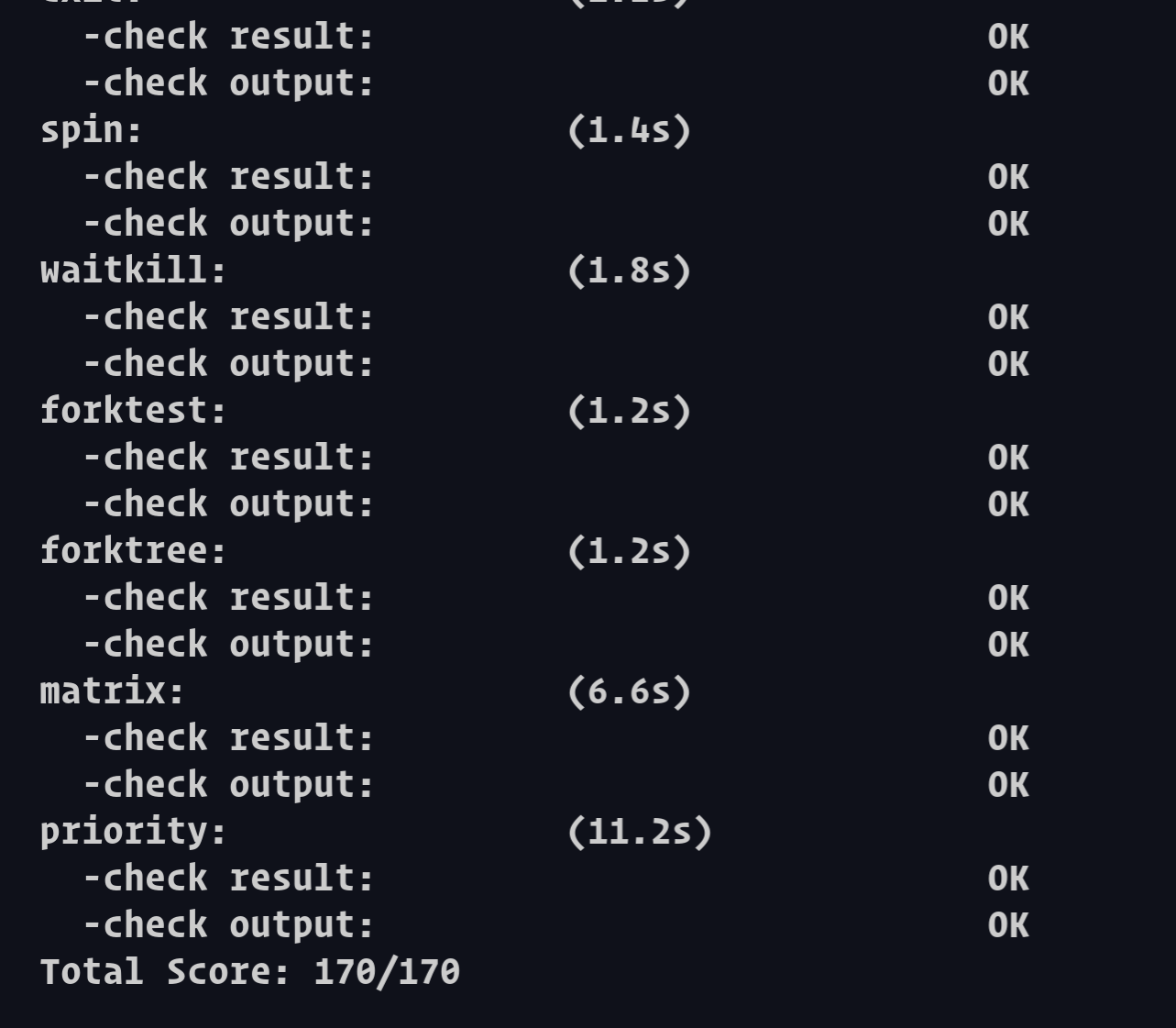
完成练习0后,建议大家比较一下(可用kdiff3等文件比较软件)个人完成的lab5和练习0完成后的刚修改的lab6之间的区别,分析了解lab6采用RR调度算法后的执行过程。执行make
grade,大部分测试用例应该通过。但执行priority.c应该过不去。
请在实验报告中完成:
请理解并分析sched_class中各个函数指针的用法,并结合Round Robin
调度算法描ucore的调度执行过程
请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计
请理解并分析sched_class中各个函数指针的用法,并结合Round
Robin 调度算法描ucore的调度执行过程
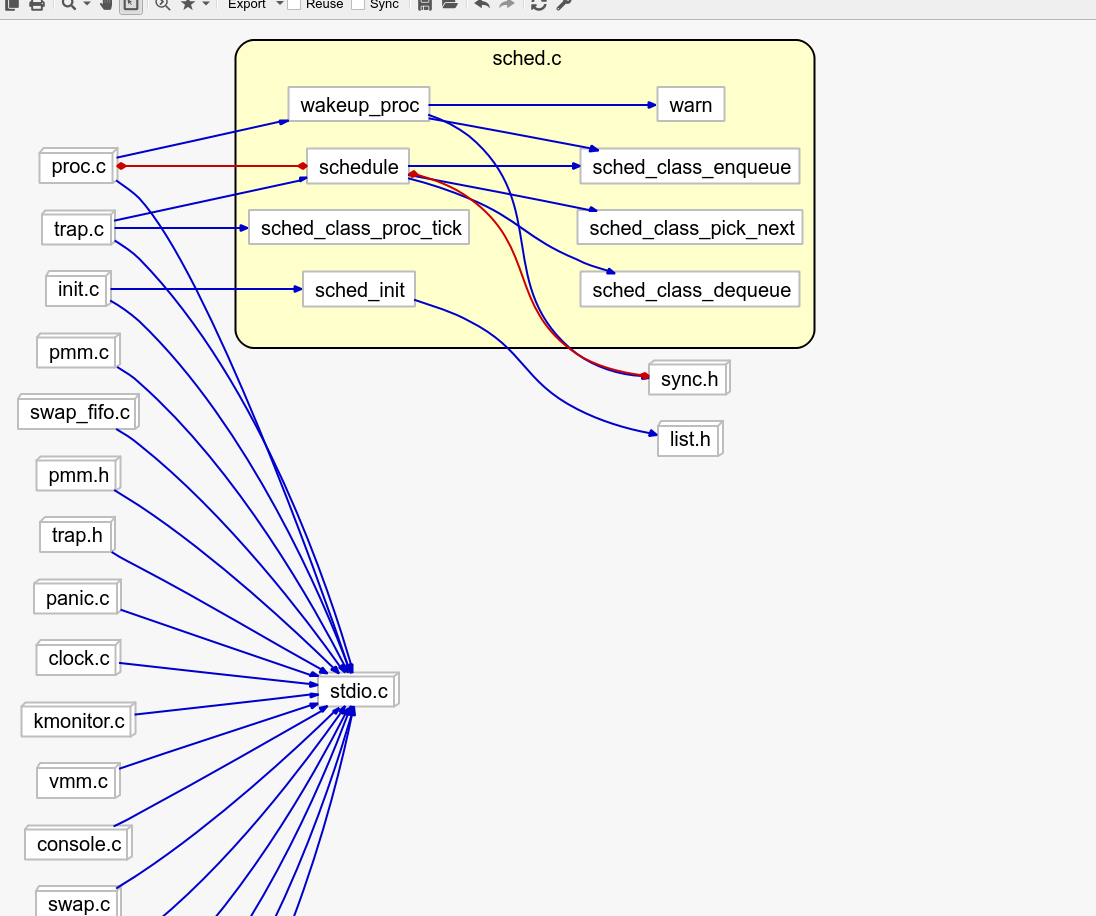
在kern/schedule/sched.h不难找到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct sched_class {const char *name;void (*init)(struct run_queue *rq);void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);struct proc_struct *(*pick_next )(struct run_queue *rq );void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);
由于时间较紧,且根据注释易于理解,此处不再赘述
在kern/schedule/default_sched.c不难找到rr算法的实现,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static void RR_init (struct run_queue *rq) 0 ;static void RR_enqueue (struct run_queue *rq, struct proc_struct *proc) if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {static void RR_dequeue (struct run_queue *rq, struct proc_struct *proc) static struct proc_struct *RR_pick_next (struct run_queue *rq) list_entry_t *le = list_next(&(rq->run_list));if (le != &(rq->run_list)) {return le2proc(le, run_link);return NULL ;static void RR_proc_tick (struct run_queue *rq, struct proc_struct *proc) if (proc->time_slice > 0 ) {if (proc->time_slice == 0 ) {1 ;
如注释所示。
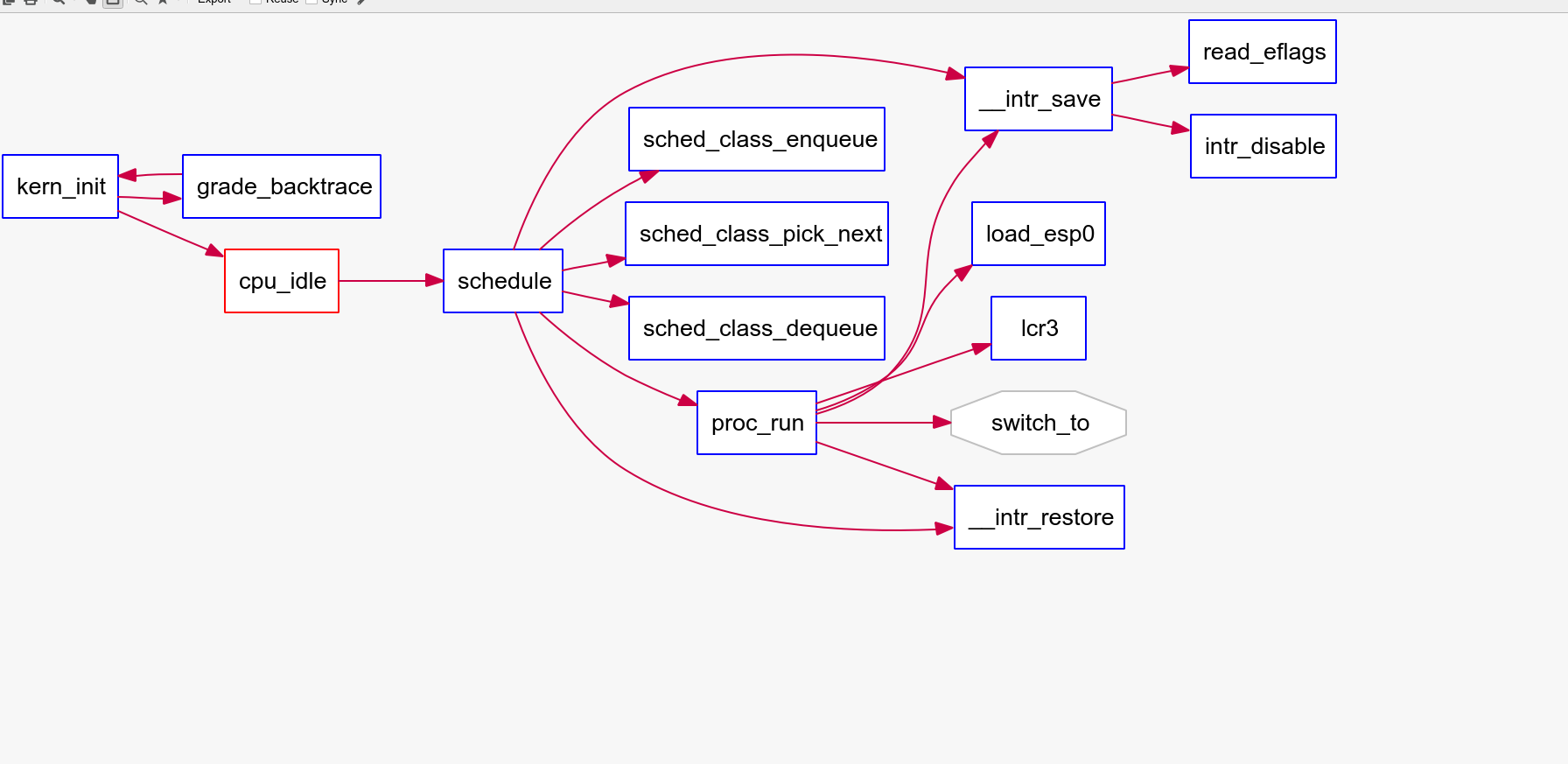
那么也就是说,ucore的RR算法,首先调用kern/schedule/sched.c中的sched_init函数进行初始化(加入list),之后初始化进程(proc目录下的函数),ucore执行cpu_idle(proc目录下)函数,调用sched_class_enqueue加入队列,启动进程计时器。之后pick_next,有可以执行的进程就dequeue,继续proc_run.
相关调用图:
请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计
多级反馈队列实际上是通过设置多个优先级不同的队列实现,其中优先级越高,时间片越高。在enqueue中,如果该进程时间片为0则不改变其优先级,大于0则降低其优先级;调度时,参照ostep的规则,如果
A 的优先级 > B 的优先级,运行 A(不运行 B);如果 A 的优先级 = B
的优先级,轮转运行A 和
B;新进程进入系统时,放在最高优先级(最上层队列);一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列);经过一段时间
S,就将系统中所有工作重新加入最高优先级队列。
练习二
练习2: 实现 Stride Scheduling 调度算法(需要编码)
首先需要换掉RR调度器的实现,即用default_sched_stride_c覆盖default_sched.c。然后根据此文件和后续文档对Stride度器的相关描述,完成Stride调度算法的实现。
后面的实验文档部分给出了Stride调度算法的大体描述。这里给出Stride调度算法的一些相关的资料(目前网上中文的资料比较欠缺)。
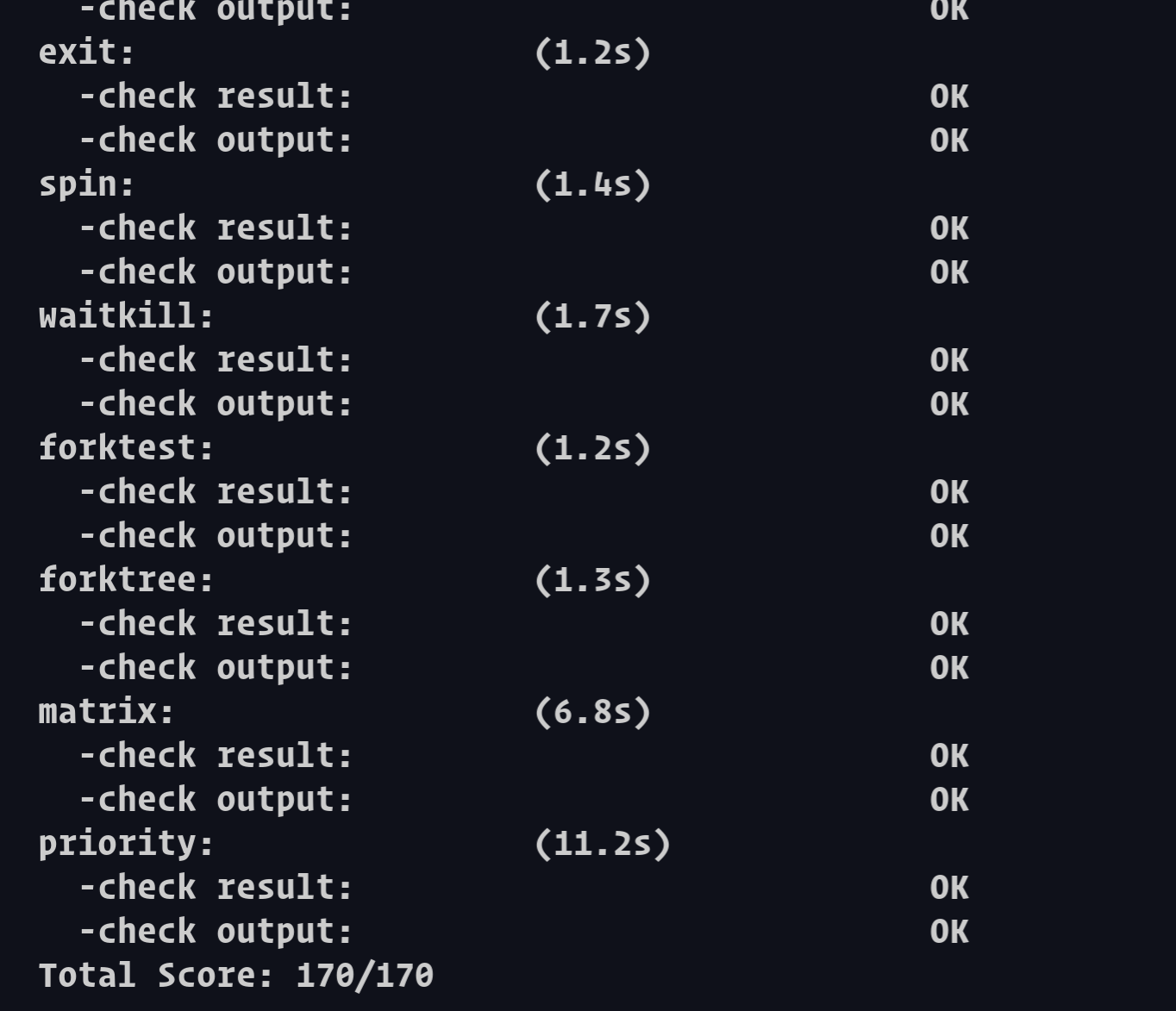
执行:make
grade。如果所显示的应用程序检测都输出ok,则基本正确。如果只是priority.c过不去,可执行
make run-priority 命令来单独调试它。大致执行结果可看附录。( 使用的是
qemu-1.0.1 )。
请在实验报告中简要说明你的设计实现过程。
所谓stride算法,实际上就是通过对每一个进程添加一个stride以及一个pass数据,每次选择最小stride(或者说离cpu最近)的进程执行,执行后该进程的stride添加步长pass.其中pass与优先级成反比,pass=BIG_STRIDE
/ priority
关于BIG_STRIDE的详细推导建议参考yuerer
具体代码实现建议参考kiprey
这里贴一下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #include <defs.h> #include <list.h> #include <proc.h> #include <assert.h> #include <default_sched.h> #define USE_SKEW_HEAP 1 #define BIG_STRIDE ((uint32_t) -1) / 2 static int proc_stride_comp_f (void *a, void *b) struct proc_struct *p =struct proc_struct *q =int32_t c = p->lab6_stride - q->lab6_stride;if (c > 0 ) return 1 ;else if (c == 0 ) return 0 ;else return -1 ;static struct proc_struct *stride_pick_next (struct run_queue *rq) skew_heap_entry_t * she = rq->lab6_run_pool;if (she != NULL ) {struct proc_struct * p =return p;return NULL ;static void stride_init (struct run_queue *rq) NULL ;0 ;static void stride_enqueue (struct run_queue *rq, struct proc_struct *proc) if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {static void stride_dequeue (struct run_queue *rq, struct proc_struct *proc) static void stride_proc_tick (struct run_queue *rq, struct proc_struct *proc) if (proc->time_slice > 0 ) {if (proc->time_slice == 0 ) {1 ;struct sched_class default_sched_class ="stride_scheduler" ,
到这里,执行make grade时,会出错。
根据网上博客,解决办法是注释掉grade.sh的221到233行,我们来看一下这一段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # found和not相等就为真 # found,not都是标志变量, # not在代码没有错误的情况下为0 # found=$(($? == 0 )),不是很清楚在干什么。。。
这一段是在check_regexps里面,okay为no时就会报错,而ucore的最终得分就是通过检查有无报错产生的。如果想蒙混过关,把这个no改成yes或者注释掉这一段代码或者把-eq改成-ne就行了
但如果每一次验收实验都只是为了验收而验收,自己什么都没学到,那还有什么意思呢?
当然对os不感兴趣的话混就得了
实际上,我们的错误是由于一个细节,在之前的kern/schedule/default_sched.c中,优先级初始化为0,而0在stride中是不能作为被除数存在的,因此需要更改kern/process/proc.c中的proc->lab6_priority为1。
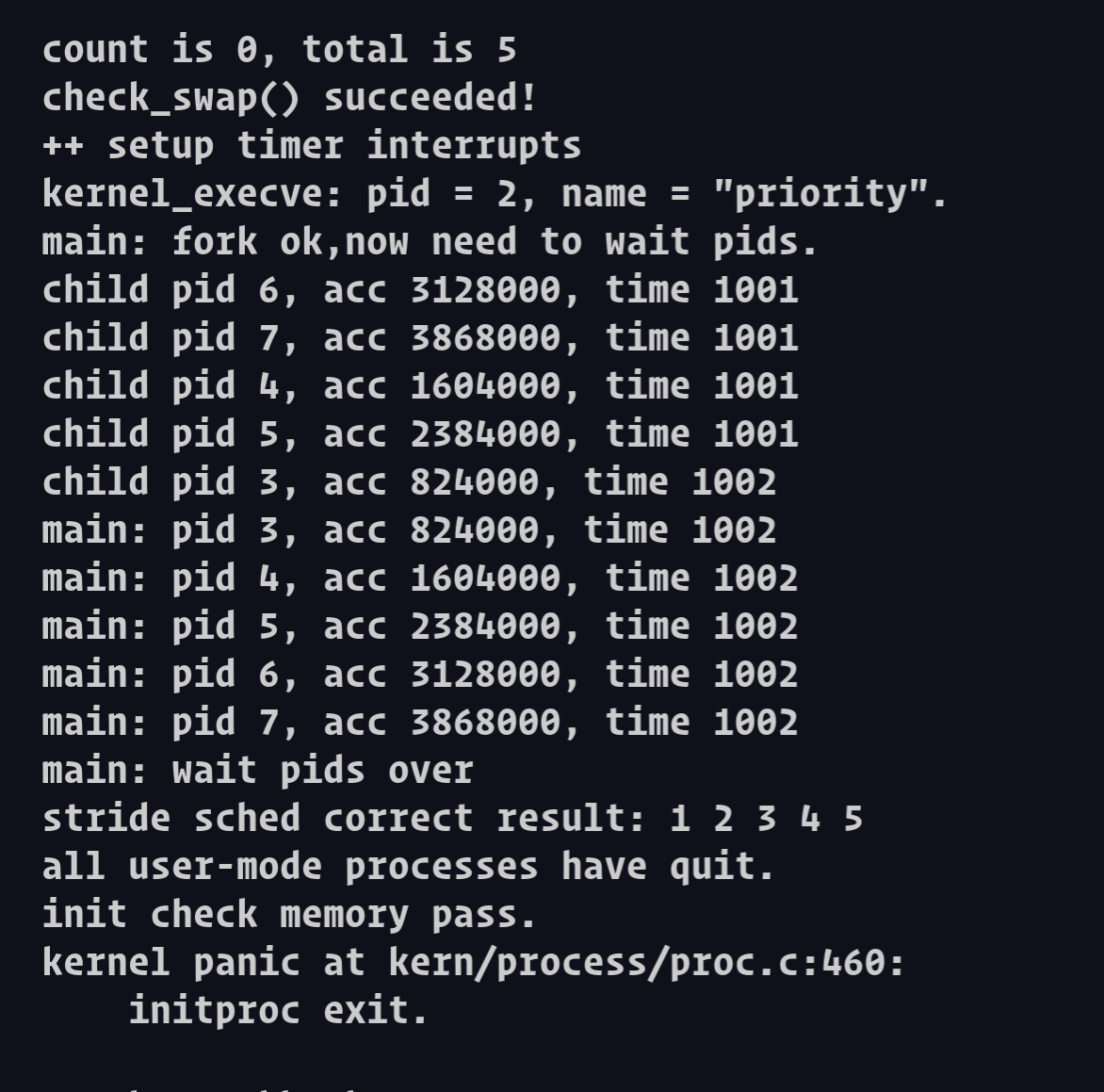
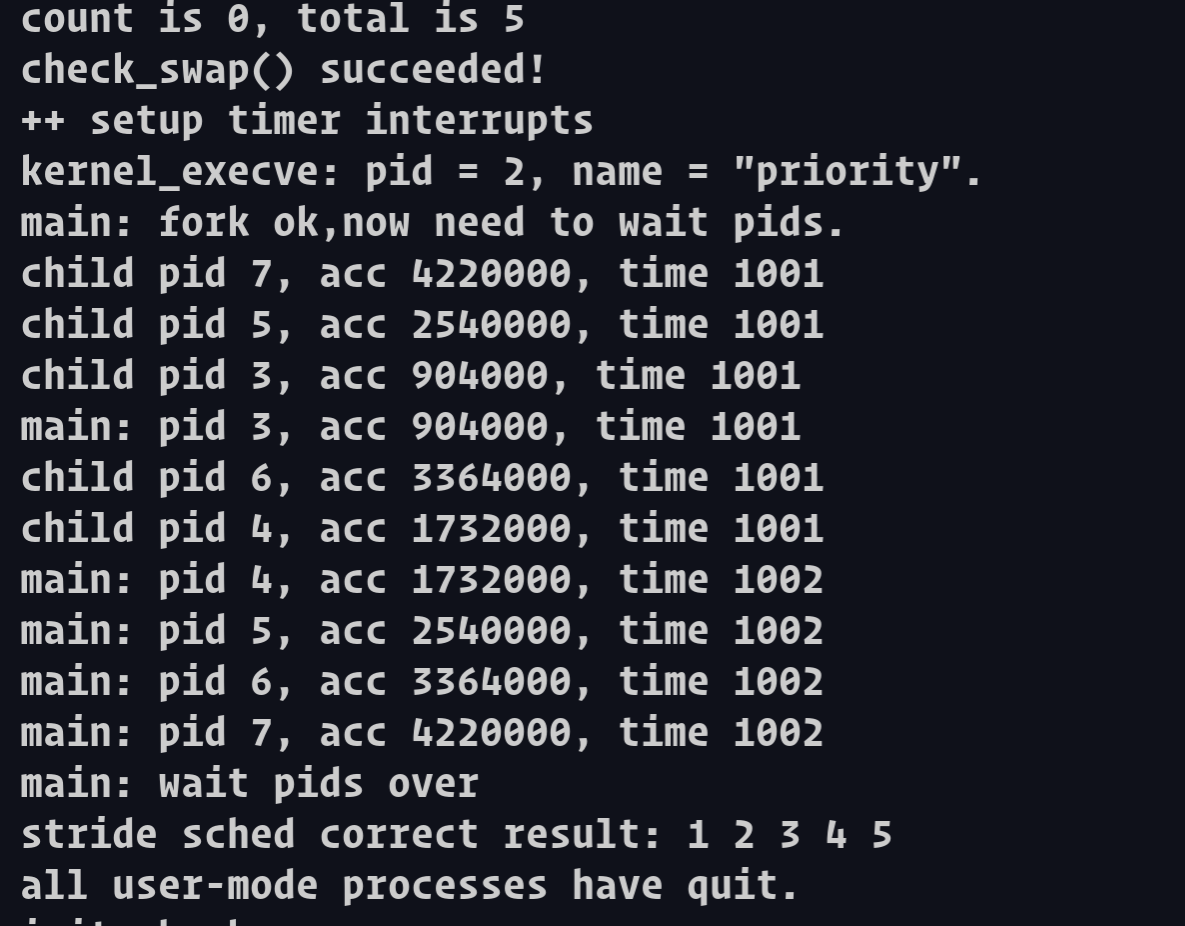
结果:
Challenge 1
扩展练习 Challenge 1 :实现 Linux 的 CFS 调度算法
在ucore的调度器框架下实现下Linux的CFS调度算法。可阅读相关Linux内核书籍或查询网上资料,可了解CFS的细节,然后大致实现在ucore中。
CFS
(完全公平调度器)实现的主要思想是维护为任务提供处理器时间方面的平衡(公平性)。它给每个进程设置了一个虚拟时钟vruntime。其中vruntime=实际运行时间∗1024/进程权重
进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但获得比较多的运行时间;CFS调度器总是选择虚拟时钟跑得慢的进程来运行,从而让每个调度实体的虚拟运行时间互相追赶,进而实现进程调度上的平衡。
CFS使用红黑树 来进行快速高效的插入和删除进程。
仍是参考PKUanonym 的仓库:ucore
先上结果:
下面分析佬的代码,
kern/schedule/cfs_sched.h没有什么大的改变,改个名字就好了
kern/schedule/cfs_sched.c中,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #define NICE_0_LOAD 1024 static int proc_cfs_comp_f (void *a, void *b) struct proc_struct *p =struct proc_struct *q =int32_t c = p->lab6_stride - q->lab6_stride;if (c > 0 ) return 1 ;else if (c == 0 ) return 0 ;else return -1 ;static void cfs_init (struct run_queue *rq) NULL ;0 ;static void cfs_enqueue (struct run_queue *rq, struct proc_struct *proc) if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {1 ;static void cfs_dequeue (struct run_queue *rq, struct proc_struct *proc) 1 ;static struct proc_struct *cfs_pick_next (struct run_queue *rq) if (rq->lab6_run_pool == NULL ) return NULL ;struct proc_struct * min_proc =if (min_proc->lab6_priority == 0 ) {else if (min_proc->lab6_priority > NICE_0_LOAD) {1 ;else {return min_proc;static void cfs_proc_tick (struct run_queue *rq, struct proc_struct *proc) if (proc->time_slice > 0 ) {if (proc->time_slice == 0 ) {1 ;struct sched_class cfs_sched_class ="cfs_scheduler" ,
Challenge 2
看着就知道工作量大,没空,也不会。
闲了再说。